Human Pose Estimation
What is Human Pose Estimation?
Human Pose Estimation (HPE) is a task in computer vision that focuses on identifying the position of a human body in a specific scene. Most of the HPE methods are based on recording an RGB image with the optical sensor to detect body parts and the overall pose. This can be used in conjunction with other computer vision technologies for fitness and rehabilitation, augmented reality applications, and surveillance.
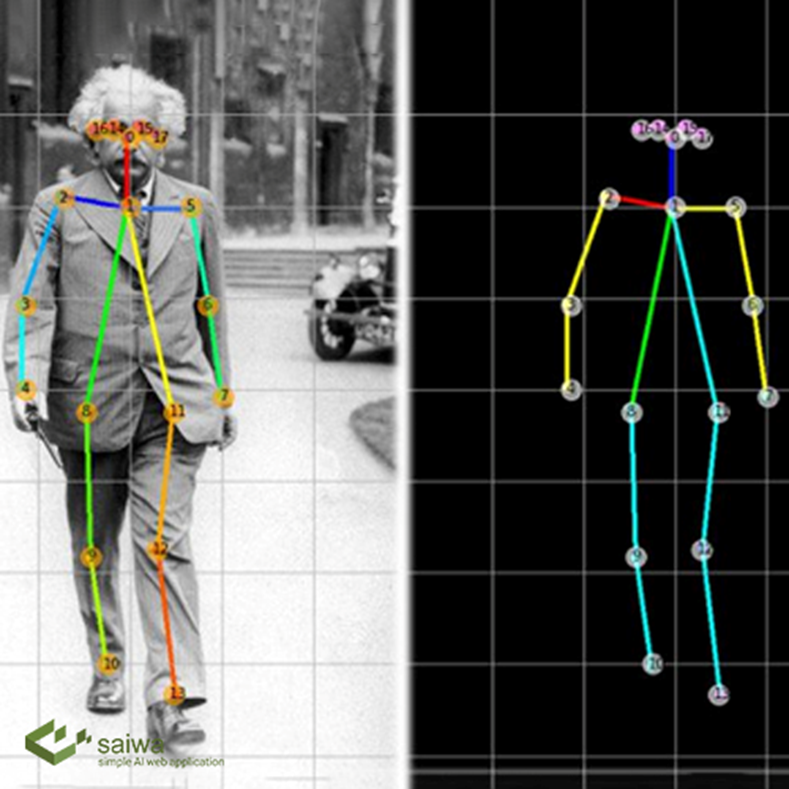
The essence of the technology lies in detecting points of interest on the limbs, joints, and even face of a human. These key points are used to produce a 2D or 3D representation of a human body model.
These models are basically a map of body joints we track during the movement. This is done for a computer not only to find the difference between a person just sitting and squatting, but also to calculate the angle of flexion in a specific joint, and tell if the movement is performed correctly.
There are three common types of human models: skeleton-based model, contour-based, and volume-based. The skeleton-based model is the most used one in human pose estimation because of its flexibility. This is because it consists of a set of joints like ankles, knees, shoulders, elbows, wrists, and limb orientations comprising the skeletal structure of a human body.

Use Cases and Applications
Human Activity and Movement
Pose estimation models track and measure human movement. They can help power various applications, for example, an AI-based personal trainer. In this scenario, the trainer points a camera at an individual performing a workout, and the pose estimation model indicates whether the individual completed the exercise properly or not.
A personal trainer application powered by pose estimation makes home workout routines safer and more effective. Pose estimation models can run on mobile devices without Internet access, helping bring workouts (or other applications) to remote locations via mobile devices.
Augmented Reality Experiences
Pose estimation can help create realistic and responsive augmented reality (AR) experiences. It involves using non-variable key points to locate and track objects, such as paper sheets and musical instruments.
Rigid pose estimation can determine an object’s primary key points and then track these key points as they move across real-world spaces. This technique enables overlaying a digital AR object on the real object the system is tracking.
Animation & Gaming
Pose estimation can potentially help streamline and automate character animation. It requires applying deep learning to pose estimation and real-time motion capture to eliminate the need for markers or specialized suits for character animation.
Pose estimation based on deep learning can also help automate capturing animations for immersive video game experiences. Microsoft’s Kinect depth camera popularized this type of experience.
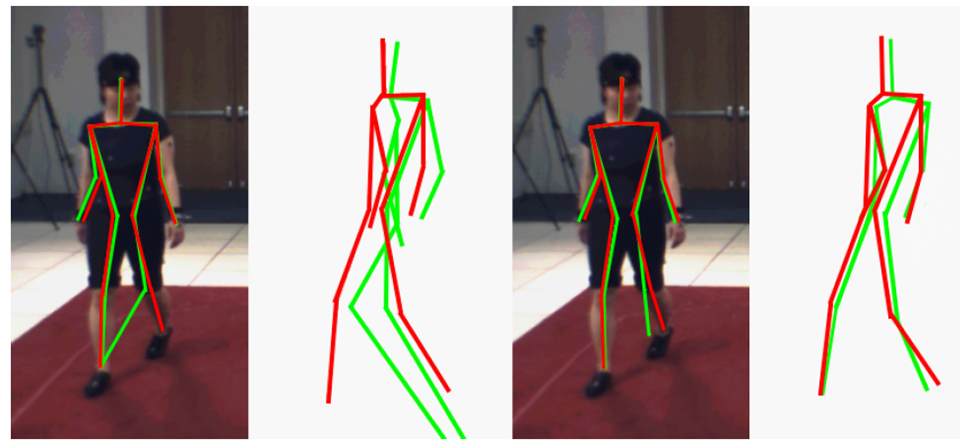
Difference Between 2D and 3D Human Pose Estimation
There are majorly two techniques in which pose estimation models can detect human poses.
2D Pose Estimation
In this type of pose estimation, you simply estimate the locations of the body joints in 2D space relative to input data (i.e., image or video frame). The location is represented with X and Y coordinates for each key point.
3D Pose Estimation
In this type of pose estimation, you transform a 2D image into a 3D object by estimating an additional Z-dimension to the prediction. 3D pose estimation enables us to predict the accurate spatial positioning of a represented person or thing.
3D pose estimation is a significant challenge faced by machine learning engineers because of the complexity entailed in building datasets and algorithms that estimate several factors, such as an image’s or video’s background scene, light conditions, and besides.
Human Pose Estimation in Saiwa
Human Pose estimation refers to detecting keypoint locations that describe the overall shape (skeleton) of an object. In saiwa, we provide human pose estimation to jointly detect human body, hand, facial, and foot keypoints in a single image. Two popular pose estimator are represented: OpenPose and MediaPipe. OpenPose is a multi-person bottom-up method while MediaPipe is top-down and in its standard version, it is single person. Different set of keypoints is extracted using each method that you may find the details in the corresponding white paper. Human pose estimation have wide applications such as motion analysis, action recognition and more. We have already make a sample yet useful service using pose estimation, i.e. “Corrective Excursive”. This service is also available with a free public demo in your user panel under Advanced Services category.
Deep Learning models
Throughout the history of Human Pose Estimation, there were multiple solutions based on classical Computer Vision, with a focus on parts and changes in colors and contrast. In the past few years, this area has been dominated by deep learning solutions, so in the following part, we will focus on them.
Deep learning solutions can be distinguished into two branches:
top-down: firstly performing person detection and then regressing key points within the chosen bounding box.
bottom-up: localize identity free key points and group them into person instances.

Top-down approaches
As stated before, within the top-down approaches, there are multiple examples with favorable results. All of them are learning using not the position of key points, but heatmaps of their location. This solution proved to result in a significantly better and more robust outcome. In this blog post, we will limit ourselves to the 3 most influential pose estimation architectures, which shaped the landscape of this branch of approaches.
Bottom-up approaches
As mentioned before, bottom-up approaches produce multiple skeletons at once, so they are often faster and more suitable for real-time solutions and also perform better in crowd scenes for multi person pose estimation.

Comments
Post a Comment