Image labeling
What is Image Labeling?
Image labeling is about identifying an image as a whole, but it can also be about identifying different aspects within an image. For example, the process is simple for images that contain a single image, such as a portrait photo. Captioning an image can be more difficult for shots with more detail, such as a wide-angle image taken in a public place. The more detailed the image tag is, the more information it can provide. For example, it might be helpful to tag an image as a mountainous landscape, but it’s even better if the mountain range can be identified. Depending on the detail of the image and the level of detail of the description, captioning your image can be a lengthy process that contains a lot of information about what’s in the image.
Why is Image Labeling Important for AI and Machine Learning?
Image labeling is a key element in the development of supervised models with computer vision capabilities. It helps train machine learning models to label entire images or identify classes of objects in an image. Here are several ways that image labeling is useful:
Development of working artificial intelligence (AI) models: Image labeling tools and techniques help highlight or capture specific objects in an image. These labels make the images machine-readable, and the highlighted images are often used as a training dataset for AI and machine learning models.
Improved Computer Vision: Image captions and annotations help improve computer vision accuracy by enabling object recognition. Training AI and machine learning with labels helps these models recognize patterns.

Methods used in image labeling
Image annotation sets a standard that computer vision algorithms try to learn from. Therefore, accurate labeling is essential in training neural networks. There are three methods for image labeling: manual, semi-automated, and synthetic.
Manual image annotation
Manual image annotation is the process of manually defining labels for an entire image or drawing regions in an image and adding textual descriptions for each region. This method involves a human annotator who carefully examines an image to identify objects, draw bounding boxes or polygons around them, and assign labels to each object.
While manual annotation can produce accurate results, it has some drawbacks such as inconsistency when multiple annotators are involved and difficulty scaling up for large datasets. To ensure consistency in labeling, annotators must be provided with clear instructions and consideration needs to be given to quality control of the labeling.
Semi-automated image annotations
Semi-automated image annotation is a method that combines automated algorithms with manual annotations to label images. This technique involves using an automated annotation tool to detect object boundaries in an image and provide a starting point for manual annotators.
The algorithm of the image annotation software is not 100% accurate, but it can save time for human annotators by providing at least a partial map of objects in the image. The human annotator then corrects any errors or adds additional labels as needed.
Semi-automated annotation tools are particularly useful when dealing with large datasets since they can speed up the labeling process while still maintaining high accuracy levels.

Synthetic image labeling
Synthetic image labeling is a method of image annotation that involves generating images automatically. This technique uses computer graphics software to create synthetic images that are similar to real-life objects or human faces and assigns known labels to them in advance.
The main advantage of using synthetic images for labeling is accuracy and cost-effectiveness since the labels are known before generating the images. Synthetic image labeling can be used when there’s a shortage of annotated data, which is common in certain applications such as autonomous vehicles, robotics, and gaming.
One limitation of synthetic image labeling is that it may not accurately represent all possible variations found in real-world scenarios. Therefore, it should be combined with other forms of annotations like manual or semi-automated annotation techniques to ensure high-quality training datasets suitable for machine learning models’ development.
Image Labeling in saiwa
Image labeling online in Saiwa is a simple technique that can be completed in several phases.
Here are some phases to manually label an image:
1. Select the image dataset
2. Establish the label classes.
3. Use labeling software to label the images.
4. Save the labeling data in a training format (JSON, YOLO, etc.).
The features of the Saiwa image labeling online service
· Promote the use of the three most common types of labeling.
· For complicated situations, an interactive interface with a few clicks is required.
· Save to commonly used labeling formats
· Labels with various overlapping and advanced
· The results can be exported and archived locally or in the individual’s cloud.
· The Saiwa team can customize services through the “Request for Customization” option.
· View and save the labeled images.

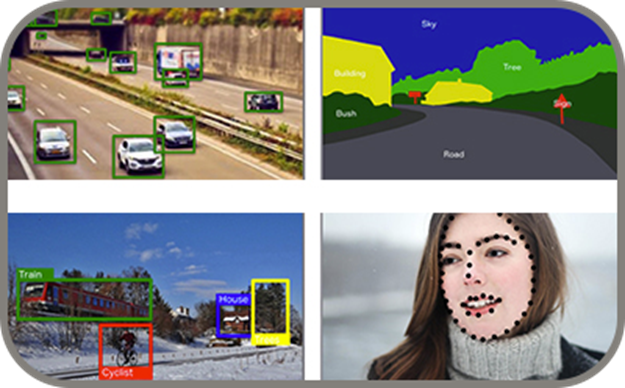
Types of Image Labeling
Image Classification
The data can be annotated to the image with the help of adding a label for the purpose of image classification. A database’s number of distinct labels corresponds to the number of classes it may categorize.
Image Segmentation
Image segmentation is the process of separating objects from the background as well as from other objects. This process utilizes computer vision models to do it. Image segmentation typically utilizes a pixel map that has the same size as the image. In this map, the 1 number denotes the presence of the object, and the 0 number denotes the absence of any annotations.
If multiple objects inside the object need to be segmented, then the segmentation process involves concatenating pixel maps for every object channel-wise. Also, it utilizes the maps as the model’s ground truth.
Object Detection
In the Object Detection process, various objects along with their accurate objects are detected with the help of computer vision. In contrast to image classification, object detection process utilizes the process of annotation of every object by utilizing bounding boxes.
The bounding box is the tiny rectangle section that has the object inside it. Tags are frequently used in conjunction with bounding box annotations to give every bounding box a label inside the image.
Pose Estimation
Distinct from every other type, Pose Estimation utilizes models of computer vision which helps to calculate the pose of the person inside the image. This process involves the detection of key points in the people’s body. Then these key points are compared with body points to calculate the pose. In explanation, the key points are used as based values for the pose estimation process.
In addition, pose estimation utilizes the process of labeling the easy coordinates with tags. So, every coordinate serves as a location of a particular key point. Further, these key points are recognized by the tags inside the image. Below figure shows the post estimation in computer vision.


Comments
Post a Comment